Wie versprochen der 2. Teil
Bevor wir starten brauchen wir das Wissen des 1. Teiles und das Programm Microsoft Speech API 5.1 (SAPI 5.1) (68 MB), downloadbar unter der Adresse http://www.microsoft.com/speech/download/old/sapi5.asp.
Dies benötigen wir, damit unser die LippenSyncro richtig zugeordnet werden kann.
In diesem Teil zeige ich mal wie man sein selbstgesprochenes bzw. auch andere Waves mit Lippen Synchro im Face Poser machen kann. Als erstes braucht man ein Wave File und es muss in dem Format Stereo, 8 oder 16 Bit und die Rate kann von 11025 Mhz bis 44100 Mhz sein (44100 Mhz is das bessere). Diese Wav speichert man unter Half-Life 2\Hl2\sound\, ist wichtig das ihr später nich wisst, wo ihr die hinspeichert um sie dann im Face-Poser zu finden.
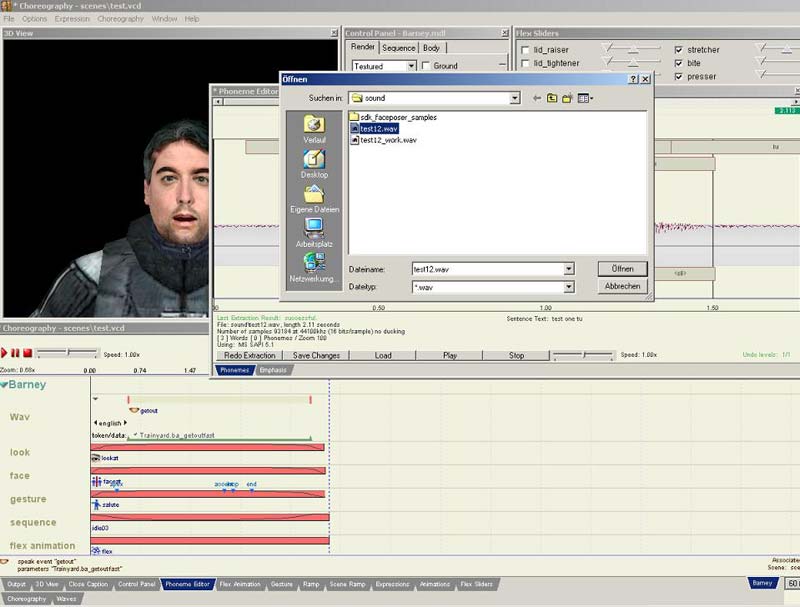
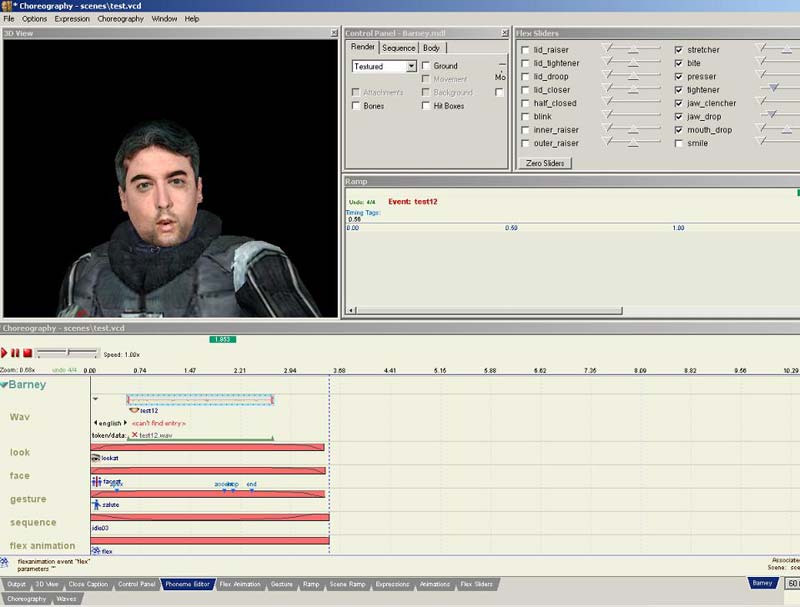
Als erstes klickt ihr im Face-Poser auf den Phoneme Editor dopplet, klickt auf Öffnen und dann müsste so ein Fenster wie ihr auf dem Bild seht erscheinen. Das Programm zeigt euch direkt den Sound-Ordner von dem Mod Verzeichnis an (ich hab bei meinem SDK Half-Life 2 ausgewählt). Jetzt öffnet ihr eure Datei, ich habe meine test12 genannt.
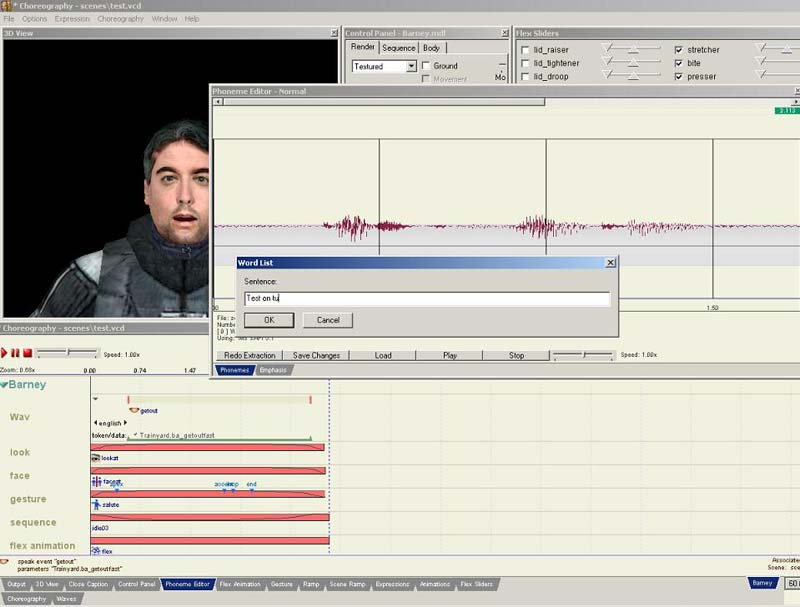
So wenn die Wave-Datei geöffnet ist klickt ihr auf Redo Extraction, dann müsste das Fenster kommen wo ihr eure Wörter eingeben müsst, die das Model sprechen soll. Hier müsst ihr das Wort genau so eingeben, wie es gesprochen wird (schaut wie ich one two bei meinem Beispiel geschieben hab) und dann klickt OK.
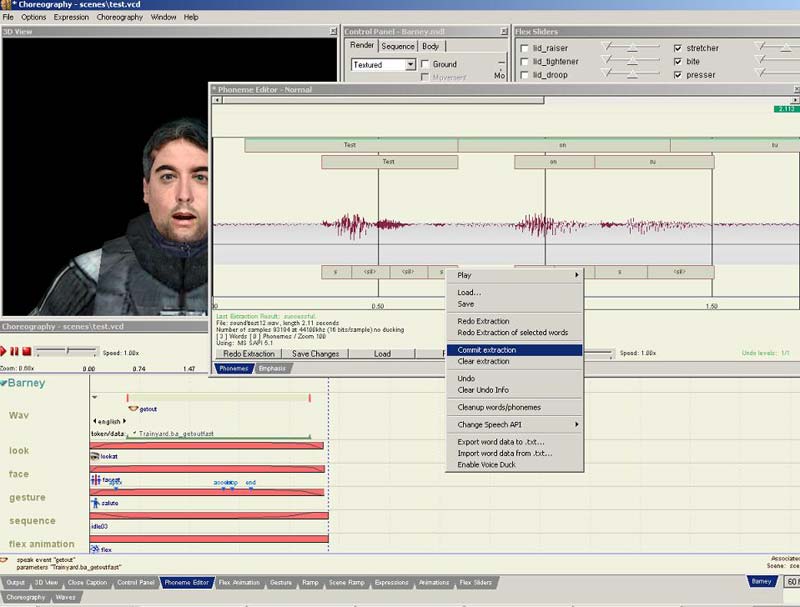
Jetzt müssten unter eurer Wave Buchstaben erscheinen und darüber der Text, den ihr eingegebn habt. Klickt mit der rechten Maustaste auf die Buchstaben und macht Commit extraction.
Wie ihr bei meinem Beispiel seht, sind die Buchstaben unten (auch Phoneme) genannt nicht ganz das was mein Model eigentlich Syncronisieren sollte. Ist aber kein Problem, einfach rechts auf das Phoneme klicken, welches Falsch ist und Edit machen. Daraufhin müsste ein Fenster erscheinen wo ihr einige Buchstaben auswählen könnt, alle ziemlich komisch gemischt aber wenn man sucht findet man schon den Buchstaben, welchen man sucht. Wenn man ihn gefunden hat einfach klicken und dann auf OK.
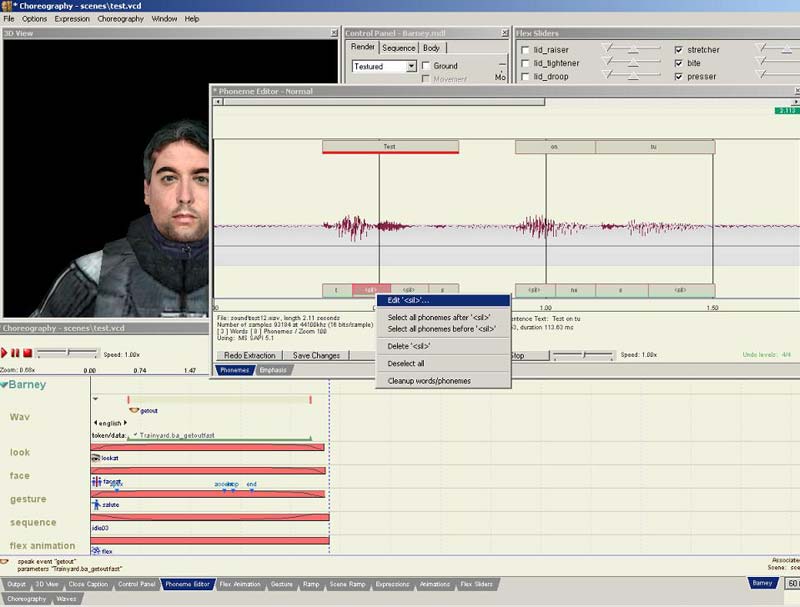
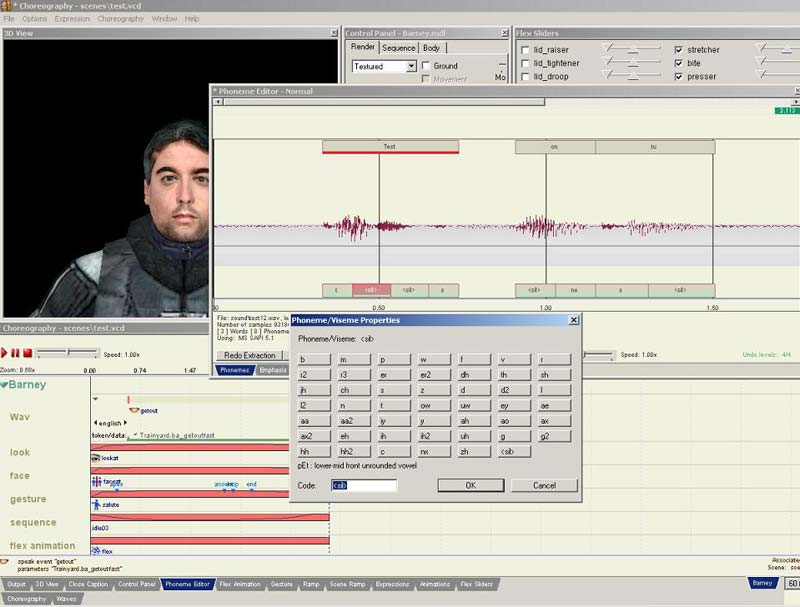
Dies macht ihr mit allen Buchstaben, die falsch sind und
macht probeweise mal Play, ob alles so aussieht wie es soll, den wenn man alles richtig gemacht hat sollte das Model jetzt die Lippen bewegen. Wenn alles OK ist machen wir Save Changes.
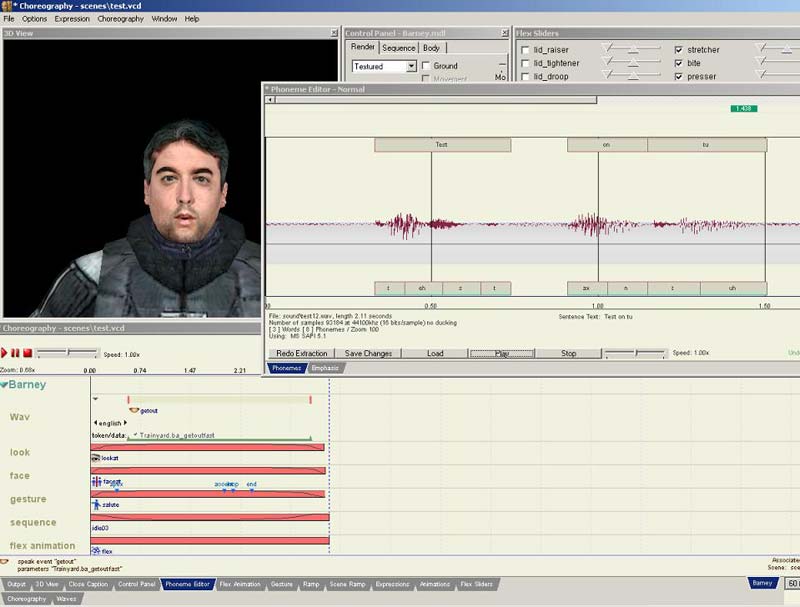
Anschließend ertsellen wir einen neuen Channel bzw. benutzen wie in meinem Beispiel den, der schon da ist. Dann ganz normal New -> Wav machen und schon müssste das Fenster erscheinen, bei dem man die Wave Dateien auswählen kann, suchen nach unserem Wave bringt übrigens nichts, es ist nicht auf der Liste. Um es doch in den Face Poser zu bekommen, müssen wir bei Sound den genauen Namen des Sounds angeben, bei mir test12.wav,
hier ist es auch wichtig, wo ihr es hingespeichert habt, wenn es in einem Unterordner ist muss zuerst der Unterordner angegeben werden, und dann die Wave (z.B. test\test12.wav).
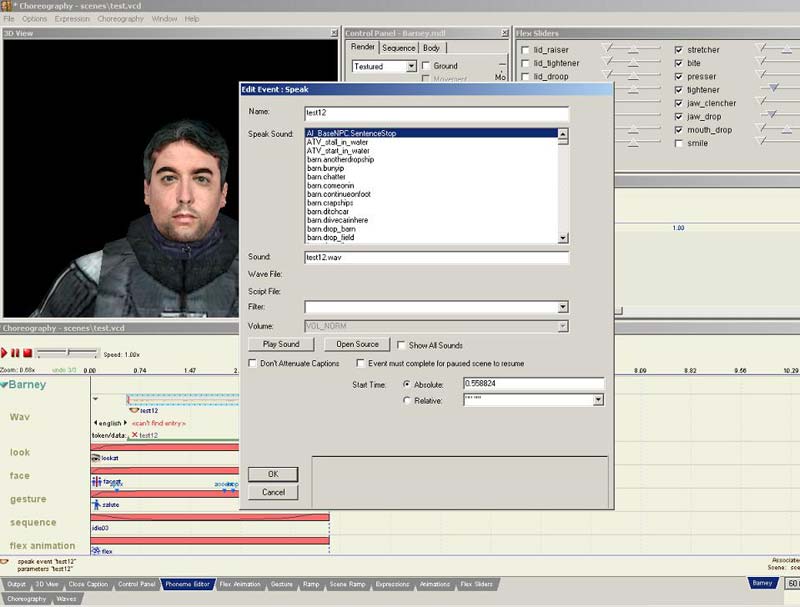 ]
]
Wenn man alles richtig gespeichert hat müsste, wenn man Die Sequence abspielt unser Model seine Lippen so bewegen wie wir es wollten, jetzt können wir ganz normal wie in Teil 1 erklärt unsere Sequence erstellen und im Spiel betrachten.
Viel Spaß beim ausprobieren, vielleicht finde ich noch genug Sachen für einen dritten Teil heraus, bis dahin,
Stay Tuned, Cya ^^